# A tibble: 87 × 14
nome altura massa cor_do_cabelo cor_da_pele cor_dos_olhos ano_nascimento
<chr> <int> <dbl> <chr> <chr> <chr> <dbl>
1 Luke Sky… 172 77 Loiro Branca cla… Azul 19
2 C-3PO 167 75 <NA> Ouro Amarelo 112
3 R2-D2 96 32 <NA> Branca, Az… Vermelho 33
4 Darth Va… 202 136 Nenhum Branca Amarelo 41.9
5 Leia Org… 150 49 Castanho Clara Castanho 19
6 Owen Lars 178 120 Castanho, Ci… Clara Azul 52
7 Beru Whi… 165 75 Castanho Clara Azul 47
8 R5-D4 97 32 <NA> Branca, Ve… Vermelho NA
9 Biggs Da… 183 84 Preto Clara Castanho 24
10 Obi-Wan … 182 77 Ruivo, Branco Branca cla… Azul acinzen… 57
# ℹ 77 more rows
# ℹ 7 more variables: sexo_biologico <chr>, genero <chr>, planeta_natal <chr>,
# especie <chr>, filmes <list>, veiculos <list>, naves_espaciais <list>Visualização de dados
Aula 3
8 de maio de 2023
Que a Força esteja com você!
Para a aula de hoje, vamos usar os dados_starwars.
Este conjunto de dados contém 14 variáveis de 87 personagens dos filmes da saga Star Wars.
No decorrer da aula, vamos introduzir outras bases de dados para exemplificar cada tipo de gráfico.

ggplot2
Exemplos iniciais de ggplot2
dados_starwars |>
filter(!is.na(genero)) |>
ggplot() +
aes(x = massa, y = altura, color = genero) +
geom_point(size = 4, alpha = 0.7) +
xlab("Massa (kg)") +
ylab("Altura (cm)") +
ggtitle("Altura e massa dos personagens",
"Estratificado por gênero") +
theme_minimal(base_size = 20) +
scale_color_discrete(name = "Gênero")

Camadas





Por que o +?
O ggplot2, diferentemente dos outros pacotes do Tidyverse, não usa o pipe (|>) porque o ggplot2 surgiu antes que o autor tomasse conhecimento do pipe.

Dica: Como escolher o gráfico mais adequado?

Gráfico de pontos (dispersão)
Geralmente usado para visualizar a associação de duas variáveis contínuas.
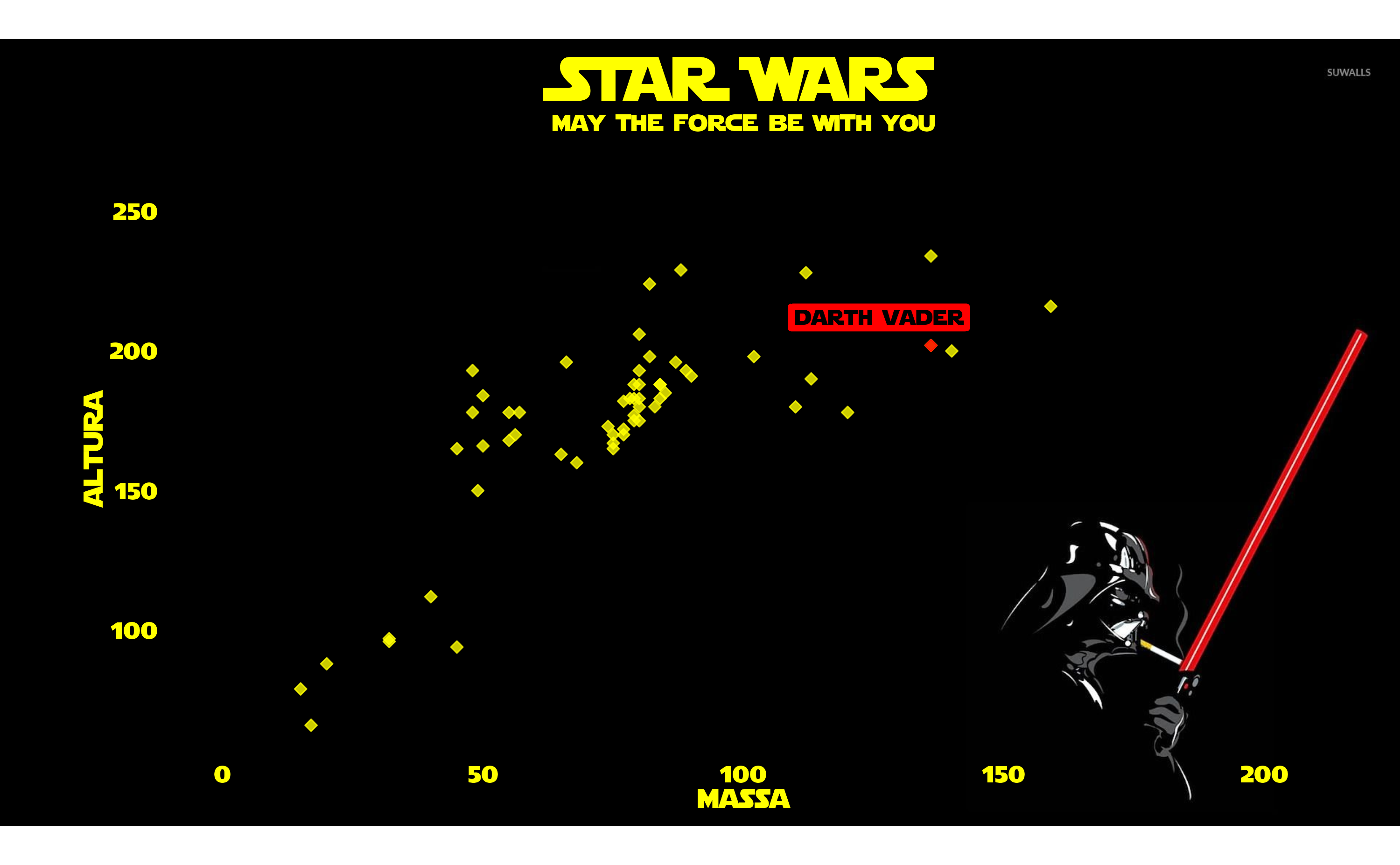
Exemplo: verificar a associação entre altura e massa nos personagens do Star Wars.
# O código abaixo gera a figura do slide
dados_starwars |>
filter(massa < 1000) |>
ggplot() +
aes(x = massa, y = altura) +
geom_point()- 1
-
Usar os
dados_starwars - 2
-
Manter apenas observações
com menos de
1.000kg de massa - 3
-
Iniciar o canvas do
ggplot2 - 4
-
Mapear massa no eixo
x
e altura no eixoy - 5
-
Adicionar geometria de pontos
comgeom_point()

ggplot2 é extremamente versátil
dados_gapminder
Para aprender o próximo gráfico, vamos usar os dados_gapminder.
Trata-se de um projeto sueco criado por Hans Rosling que coleta dados sobre diversas tendências globais. Na parte dos dados que vamos utilizar, temos informações de 1952 a 2007 (intervalos de 5 anos).
Estes dados possuem 1.704 observações e 6 variáveis, sendo elas: pais, continente, ano, expectativa_de_vida, populacao, pib_per_capita.
![]()
PIB per capita do Brasil


dados_gapminder |>
filter(pais == "Brasil") |>
ggplot() +
aes(x = ano, y = pib_per_capita) +
geom_line(linewidth = 2, color = "darkslateblue") +
scale_x_continuous(breaks = seq(1952, 2007, 5)) +
scale_y_continuous(labels = scales::dollar_format(prefix = "R$ ",
decimal.mark = ",",
big.mark = ".")) +
labs(x = "Ano", y = "PIB per capita",
title = "PIB per capita do Brasil ao passar dos anos",
subtitle = "De 1952 a 2007",
caption = "Fonte: Gapminder") +
theme_minimal(base_size = 16, base_family = "Charter")
Como os filmes da Pixar foram avaliados?
Para o próximo gráfico, vamos tentar responder a seguinte pergunta:
“Segundo a CinemaScore, qual a nota mais recebida pelos filmes da Pixar?”
Para isso, vamos usar outra base de dados do pacote dados, chamada pixar_avalicao_publico.
![]()
Exemplo de gráfico de barras
# Este código gera o gráfico abaixo
pixar_avalicao_publico |>
count(nota_cinema_score) |>
ggplot() +
aes(x = nota_cinema_score, y = n) +
geom_col()- 1
-
Usar a base
pixar_avalicao_publico - 2
-
Contar número de filmes
em cada nota - 3
-
Iniciar o canvas do
ggplot2 - 4
-
Mapear os eixos
xey - 5
-
Adicionar a geometria do
gráfico de barras

Gráfico de barras após ajustes
# O código abaixo gera o gráfico do painel ao lado
pixar_avalicao_publico |>
rename(nota = nota_cinema_score) |>
count(nota) |>
mutate(
nota = forcats::fct_na_value_to_level(nota,
"Sem escore"),
nota = factor(nota,
levels = c("A-", "A",
"A+",
"Sem escore")),
cor = dplyr::case_when(nota == "A" ~ "Colorido",
.default = "Cinza")
) |>
ggplot() +
aes(x = nota, y = n, fill = cor) +
geom_col(width = 0.5, show.legend = FALSE) +
scale_fill_manual(values = c("gray25", "darkorange")) +
labs(title = "A maioria dos filmes da Pixar (n = 13) receberam nota A.",
x = "Nota segundo CinemaScore",
y = "Número de filmes") +
theme_classic(base_size = 18, base_family = "Charter")- 1
-
Pegar base da Pixar de
avaliação do público - 2
-
Renomear variável
nota_cinema_score - 3
-
Contar o número de
filmes com cada nota - 4
-
Transformar
NAno
valor “Sem escore” - 5
-
Reordenar as notas
da menor para a maior - 6
-
Criar variável para
colorir barra principal - 7
-
Iniciar o canvas do
ggplot2 - 8
- Mapear variáveis do gráfico
- 9
-
Adicionar a geometria
do gráfico de barras,
retirar legenda e
mudar largura das barras - 10
-
Modificar as cores
do preenchimento - 11
- Adicionar título e rótulos
- 12
-
Modificar tema,
tamanho e
família da fonte

Histograma
Histogramas são úteis para avaliarmos a distribuição de uma variável numérica.
Para criar histogramas, usamos o geom_histogram(). Para isso, precisamos apenas do atributo \(x\) (o eixo \(y\) é construído de forma automática).
Na sequência, podemos observar um exemplo de histograma das notas dos filmes da Pixar no Rotten Tomatoes.

Exemplo de histograma “mais bonito”
pixar_avalicao_publico |>
ggplot() +
aes(x = nota_rotten_tomatoes) +
geom_histogram(fill = "cyan4") +
labs(x = "Nota segundo críticos do Rotten Tomatoes",
y = "Contagem",
title = "Como se distribuem as notas segundo os críticos do Rotten Tomatoes?",
subtitle = "Dados de 24 filmes da Pixar",
caption = "Fonte: Wikipedia") +
theme_light(base_size = 16, base_family = "Charter")
Box plot
Os box plots são úteis para estudar a distribuição de uma variável, especialmente ao comparar várias distribuições.
Para construir um box plot, usamos o geom_boxplot(). Para tal, usamos atributos \(x\) e \(y\), mapeando uma variável categórica para o atributo \(x\).

Box plot após ajustes
dados_gapminder |>
filter(ano == 1952) |>
ggplot() +
aes(x = continente, y = expectativa_de_vida, color = continente) +
geom_boxplot(show.legend = FALSE) +
theme_classic(base_size = 16, base_family = "Charter") +
labs(x = "Continente", y = "Expectativa de vida (em anos)",
title = "Como se distribuía a expectativa de vida em cada continente em 1952?",
caption = "Fonte: Gapminder") +
annotate("text", x = 1, y = 65,
label = "Em 1952,\na África tinha\numa expectativa\nde vida\nde 38,8 anos.",
size = 5,
family = "Charter")
Dica: Extensões do ggplot2
O
ggplot2é muito potente, mas não possui todos os gráficos possíveisPor conta disso, a comunidade desenvolve extensões que vão desde pacotes com novos temas ou cores, geometrias, eixos ou até a possibilidade de criar calendários customizados 😂
A equipe do Tidyverse mantém uma lista curada de extensões do
ggplot2

Dica de leitura sobre visualização
- Data Visualization: A Practical Introduction
- Como criar visualizações efetivas
- Quais visualizações funcionam e quais não
- Como criar vários tipos de gráficos em
ggplot2 - Como refinar os gráficos para apresentação

Referências
Wickham, Hadley. 2010. “A layered grammar of graphics”. Journal of Computational and Graphical Statistics 19 (1): 3–28. https://doi.org/10.1198/jcgs.2009.07098.
Wilkinson, Leland. 2005. The Grammar of Graphics. Springer-Verlag. https://doi.org/10.1007/0-387-28695-0.